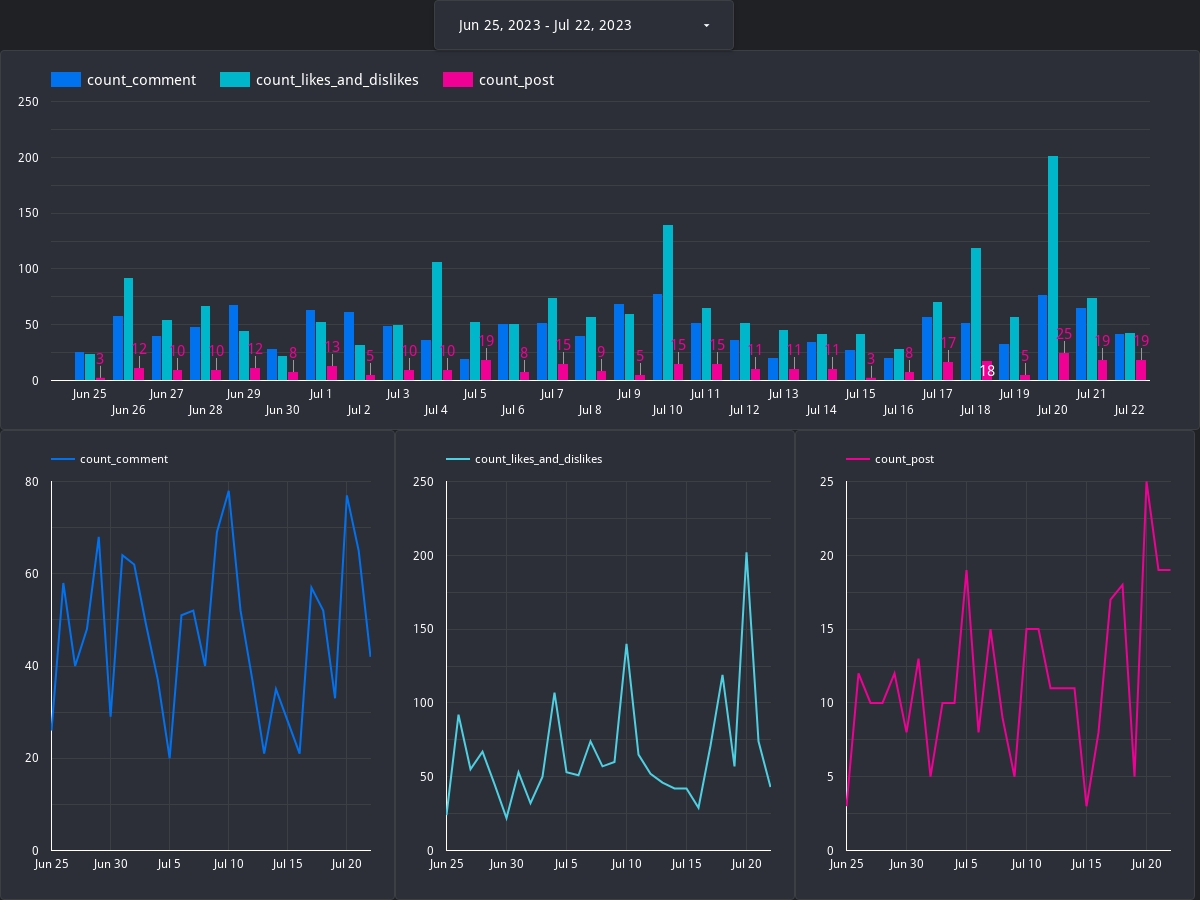
最終的にできたもの。このレポートが毎朝送られるようになる。
何がしたいのか?
個人でサービスを作って運営していると、ユーザーのアクティビティが日次でどの程度あるのか知りたくなるのが人の性だろう。自分も健常者エミュレータ事例集というサービスを運営していて、投稿数がどの程度なのか、コメント数がどの程度なのかをできれば毎日知りたい。
文化祭でゲイポルノビデオ作品を切り貼りしたポスターを作ってはいけない - 健常者エミュレータ事例集 学校
SQLをたたけば集計はできる。でも毎日SQLを書くのは面倒くさい。だから、業務で培った知識をもとに「データ基盤」を作ることにした。
まずはやりたいことを言語化してみる。
- 「健常者エミュレータ事例集」(自分でやってる個人サービス)の日次の投稿数とかコメント数とかいいね・よくないね数を知りたい
- レポーティングまで自動化してほしい。自分で知りに行くのは面倒なので、プッシュで通知してほしい。
- コストはかけたくない
この記事では、上記のようなわがまま要件を満たすようなお手軽データ基盤を作った時の記録である。まずは基盤の全体像について説明したのち、個々のコンポーネントの詳細に入って説明してく。同様の基盤を作ろうとするエンジニアの参考になれば幸いである。
基盤概要
ざっくりと概要を文字起こしする。
- まず、Cloud FunctionsでLightsailインスタンス上で動いているMySQLにアクセスし、データを取り出し、BigQueryに格納する
- この際、INFORMATION_SCHEMAを利用する形で、すべてのテーブルからデータを取り出すようにする
- 次に、dbt Cloudを利用してデータを変換し、欲しい数字が格納されたテーブルを作る
- 最後に、Looker Studioで管理人のスマホにレポート送信する。
図式化すると以下のようになる。
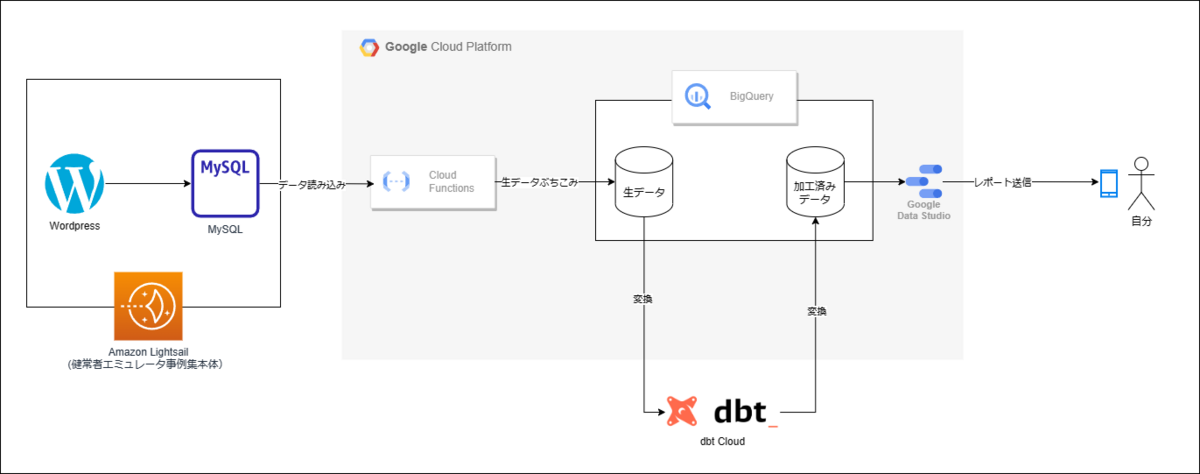
基盤の全体像
この基盤のいいところ:
-
とにかくコストが低い
- Cloud Functionsは無料
- dbt CloudもDeveloperプランなので無料
- Google Data Portal(Looker Studio)も無料
- BigQueryのみ課金する必要があるが、月3円とかのレベルなので、激安
-
管理の手間がほぼゼロ
- 全部フルマネージドサービスなため
ただし、ワークフロー管理などは特にしておらず、時間差実行で管理している(管理と呼んでいいのか?)形式なので、エラーには弱いかもしれない。今のところ起きたことがないが…
各種コンポーネントについて
それぞれのコンポーネントの中身について細かく見ていく
Cloud Functions
やっていることとしては、「MySQLのデータを全部BigQueryに入れる」だけである。
代替としてAWSのGlue Jobを考えたが、Too Machすぎるのと、BigQueryへのコネクション接続がどうしてもうまくいかずやめた。
処理の流れは以下のようになる。
- 一度INFORMATION_SCHEMAにアクセスしてすべてのテーブル名を取り出す
- それぞれのテーブルに対して抽出処理をかけ、parquetファイルを作成する
- parquetファイルをBQに対してロードする
プログラムの中身はこんな感じである。コメントで英語と日本語が混ざっているのはGithub CopilotとChatGPTを使った痕跡である。この関数が毎日深夜24時に実行され、BigQueryにデータがロードされる。
import os
import pandas as pd
from sqlalchemy import create_engine, text
from google.cloud import bigquery
from concurrent.futures import ThreadPoolExecutor
# 環境変数から設定を読み込み
MYSQL_HOST = os.environ["MYSQL_HOST"]
MYSQL_USER = os.environ["MYSQL_USER"]
MYSQL_PASSWORD = os.environ["MYSQL_PASSWORD"]
MYSQL_DB = os.environ["MYSQL_DB"]
BQ_DATASET = os.environ["BQ_DATASET"]
def process_table(table_name, engine):
# テーブルのデータを取得し、Pandas DataFrameに変換
df = pd.read_sql_table(table_name, engine)
parquet_filename = f"/tmp/{table_name}.parquet"
df.to_parquet(parquet_filename)
# BigQueryにデータをロード
bq_client = bigquery.Client()
dataset_ref = bq_client.dataset(BQ_DATASET)
table_ref = dataset_ref.table(table_name)
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.PARQUET
job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE
job_config.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
)
with open(parquet_filename, "rb") as source_file:
job = bq_client.load_table_from_file(
source_file,
table_ref,
job_config=job_config,
) # API request
job.result() # Waits for the job to complete.
print(f"Loaded {job.output_rows} rows into {BQ_DATASET}:{table_name}.")
def extract_and_load(request):
# MySQLに接続
engine = create_engine(
f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}/{MYSQL_DB}"
)
# information_schemaからテーブル名を取得
with engine.connect() as connection:
result = connection.execute(
text(
f"SELECT TABLE_NAME FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{MYSQL_DB}'"
)
)
table_names = [row[0] for row in result]
# Create a ThreadPool and process each table in parallel
with ThreadPoolExecutor() as executor:
executor.map(lambda table_name: process_table(table_name, engine), table_names)
if __name__ == "__main__":
extract_and_load(None)BigQuery
- こいつを使いたかった。もはや説明不要のデータウェアハウス。
- 生データを入れる用のデータセットと加工済みデータを入れる用のデータセットを作っている
- 細かい説明をすることがないので省略する。
Wordpressのデータモデリングとdbt Cloud
- 自分が業務で培った知識の中に「カラム名や値の中身からから何となく意味を推測し、立証してデータの意味を確定させていく」スキルがある。私はこのスキルを「Guess and Verify」と呼んでいる(経済学からとってきた)
- 日次でのページ投稿数やコメント投稿数などを抽出するためには、Wordpressにおけるデータの仕様について理解する必要がある。意外と難しかったので、やったことをメモする。
Wordpressのデータモデリングを理解する
- 歴史の長いソフトウェアであることもあり、Wordpressのデータベース設計は結構洗練されている。わかりやすかったが、それなりに理解が必要になる箇所なので、いろいろ学習する。
- ざっくりいうと、Wordpressにおけるデータには2種類ある。「公式由来のデータ」と「プラグイン由来のデータ」である。
- 公式由来のデータは投稿内容(wp_posts)やコメント内容(wp_comments)のデータが該当し、ドキュメントも充実していてわかりやすい。
- WordPress
- 一方で、プラグイン由来のデータは記事につけられた「いいね」の数や「よくないね」の数、およびコメントにつけられた「いいね」の数や「よくないね」の数などが該当し、ドキュメントはない場合が多い。集計するためには自力でSQLを叩いて道筋を立てることが必要となる。
「いいね」と「よくないね」はプラグイン由来
コメントにつけられた「いいね」と「よくないね」はプラグイン由来
余裕もないのに寄付をするべきではない - 健常者エミュレータ事例集 やらないほうがよいこと
-
ドキュメントを読んだ感じ、投稿数とコメント数に関しては簡単に集計できそう。
- wp_postsのidのユニークカウント=投稿数
- wp_commentsのcomment_idのユニークカウント=コメント数
-
一方で、記事にいいね/よくないねをつける機能はLIKEBTNというプラグイン由来なので、当然Wordpressの公式ドキュメントにはない。こちらはSQLをたたきながら推測していくことになる。
- WordPress
-
最終的に以下のようなSQLを作り、dbt Cloud上にデプロイする。
中間テーブル(stg) 投稿数集計用
select
*
from {{source('bitnami_wordpress', 'wp_posts')}}
where
post_status = 'publish'
and post_type = 'post'コメント数集計用
select
*
from {{source('bitnami_wordpress', 'wp_comments')}}
where
comment_approved = '1'記事についたいいね数・よくないね数集計用
select
*
from {{source('bitnami_wordpress', 'wp_likebtn_vote')}}KPI集計用(report)
with count_post as (
select
cast(post_date as date) as date,
count(distinct id) as count_post
from
{{ref('stg_posts')}}
group by
cast(post_date as date)
),
count_comment as (
select
cast(comment_date_gmt as date) as date,
count(distinct comment_id) as count_comment
from {{ref('stg_comments')}}
group by
cast(comment_date_gmt as date)
),
count_likes_and_dislikes as (
select
cast(created_at as date) as date,
count(distinct id) as count_likes_and_dislikes
from {{ref('stg_likes_and_dislikes')}}
group by cast(created_at as date)
)
select
count_post.date,
count_post.count_post,
count_comment.count_comment,
count_likes_and_dislikes.count_likes_and_dislikes
from count_post
left join count_comment on count_post.date = count_comment.date
left join count_likes_and_dislikes on count_post.date = count_likes_and_dislikes.dateLooker Studio
- Bigqueryに接続
- デイリーでメールアドレスに対してレポートを送信してくれるように設定する
まとめ
構築にかかった時間は2週間程度で、仕事が終わった後ちまちま作っていた感じである。 Wordpressのデータモデリングを理解するのが一番時間かかったと思う。結構大変だった。